
Jorge Gracia
The kickoff meeting of the newly created ’European network for Web-centred linguistic data science‘ (NexusLinguarum in its short name) took place in Brussels, Belgium, on 28 October 2019. The meeting brought together representatives of the 33 countries constituting the initial network to discuss the objectives, the plans for implementing the different networking tools, and the scope and goals of the different working groups, as well as to elect the action’s management board. The initial group consisted of a broad network of experts from different areas, like computer science, semantic web, artificial intelligence, linguistics, humanities, etc. That was the beginning of an exciting journey towards building a common ecosystem to support research on linguistic data science in a Web-centred context.
We understand linguistic data science as a subfield of the growing data science field that focuses on the systematic analysis and study of the structure and properties of linguistic data at a large scale, along with methods and techniques to extract new knowledge and insights from it. Linguistic data science is concerned with providing a formal basis to the analysis, representation, integration and exploitation of linguistic data for language analysis (e.g. syntax, morphology, terminology, etc.) and language applications (e.g. machine translation, speech recognition, sentiment analysis, etc.).
NexusLinguarum will last for four years and is funded by the European Cooperation in Science and Technology (COST) organization, which supports such highly competitive projects (COST Actions) by financing research networks on emerging issues, through mechanisms such as research visits, organization of congresses, scientific meetings, summer schools, etc.
To enable the study of linguistic data in the most productive and efficient ways, the NexusLinguarum COST Action is set to enhance the construction of an ecosystem of multilingual and semantically interoperable linguistic data at the scale of the Web. To this end, methods and techniques of the Semantic Web, Natural Language Processing and Language Resources are studied and combined. Such an ecosystem could reduce language barriers in Europe (and eventually beyond) and favour both electronic commerce and cultural exchange between countries with different languages. Another objective is to support minority languages whose technological support is currently limited.
Through the study of Web-centred linguistic data science, we will be able to better understand the nature of language, through innovative methods for the representation, integration and comparison of linguistic data. Furthermore, since language is the medium in which human knowledge is transmitted, this field has the potential to decisively influence studies that use natural language for knowledge sharing, as is the case of the humanities, the legal domain, journalism, social sciences, etc.
Some of the main research coordination objectives of NexusLinguarum are to:
- propose, agree upon and disseminate best practices and standards for linking data and services across languages
- organise activities to foster collaboration and communication across communities, such as scientific workshops involving broader communities to reach agreement on best practices;
- collect and analyse relevant use cases for linguistic data science and develop prototypes and demonstrators that will address some prototypical cases.
Furthermore, we plan to work out a curriculum for a Europe-wide master degree that the participating institutions could adopt to train a new generation of researchers in the area, thus introducing linguistic data science in a cross-discipline academic infrastructure. Currently we count on participants from 42 countries (37 COST Countries, 3 Near Neighbour Countries, and 2 International Partner Countries). So far, 137 members have joined the different working groups (WGs), a number which is steadily growing since the network is still open to new participants.
NexusLinguarum is organised in five working groups, four technical ones and a one for management activities:
WG1 – Linked data-based language resources. This WG lays the foundations to develop best practices for the evolution, creation, improvement, diagnosis, repair and enrichment of linguistic linked open data (LLOD) resources and value chains.
WG2 – Linked data-aware NLP services. This WG focuses on the application of linguistic data science methods including linked data to enrich NLP tasks in order to take advantage of the growing amount of linguistic (open) data available on the Web.
WG3 – Support for linguistic data science. This WG aims to foster the study of linguistic data by following data analytic techniques at a large scale in combination with LLOD and linked data-aware NLP techniques.
WG4 – Use cases and applications. This WG focuses on studying use cases and practical applications of the relevant technologies involved in the Action.
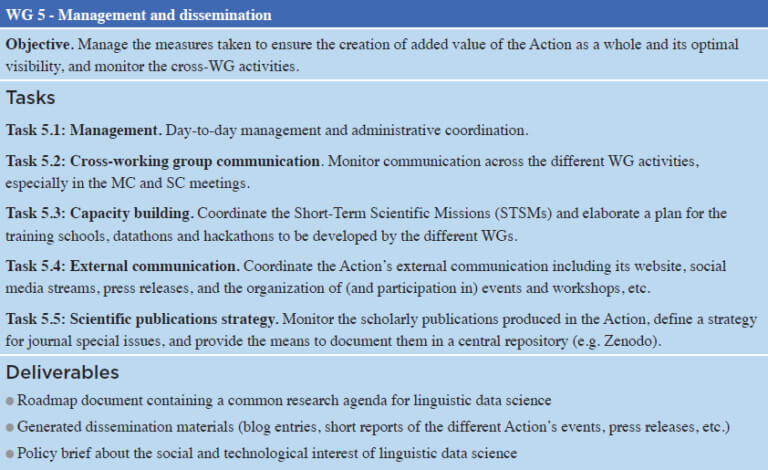
WG5 – Management and dissemination. This WG takes care of the measures to be taken to ensure the creation of added value of the Action as a whole, to ensure its maximum visibility, and to monitor the cross-WG activities.
All these WGs have already started their activities, although they are still in initial phases. One of the fist outcomes to be delivered by NexusLinguarum is a study of use case definitions, which is currently under development by WG4. The following use cases are being analysed currently: Humanities and Social Sciences, Linguistics (Media and Social Media, and Language Acquisition), Life Sciences, and Technology (Cybersecurity and FinTech). The idea is to analyse the current state-of-the-art on each of these topics, analyse their needs and challenges, and determine the techniques and ideas of linguistic data science that might improve them, in close collaboration with the other WGs.
The other three technical WGs are also conducting initial surveys and analysing related projects and initiatives to set the ground for further development. Collaboration with other projects and initiatives are already on course, for instance with the W3C Linked Data for Language Technologies community group in relation to the ongoing discussion towards a consolidated Linked Open Data vocabulary for linguistic annotations, in the context of WG1.
NexusLinguarum has already organised two face-to-face meetings of its Management Committee (MC): in Brussels in October 2019 (kickoff meeting), and in Prague (Czech Republic) in January 2020 collocated with the first WG meetings. The next MC + WGs meeting is due to take place in October 2020 in Lisbon (Portugal). In addition, regular teleconferences take place to enable and monitor the scientific progresses of the different WGs, and a number of training schools and scientific events are planned for 2021.
More information can be found at https://nexuslinguarum.eu/.
New participants can join the network through this registration form.
NexusLinguarum Core Group

Chair. Jorge Gracia
University of Zaragoza, Spain
Vice-chair. John McCrae
National University of Ireland, Galway, Ireland
Grant Holder Scientific representative. Elena Montiel-Ponsoda
Universidad Politécnica de Madrid, Spain Science
Communication manager. Thierry Declerck
DFKI, Germany
Short Term Scientific Missions STSM coordinator. Penny Labropoulou
Athena Research Center, Greece
Inclusiveness Target Countries ITC Conference Grant coordinator. Vojtech Svatek
University of Economics, Prague, Czech Republic
WG1 leader. Milan Dojchinovski
Czech Technical University in Prague, Czech Republic
WG1 co-leader. Julia Bosque-Gil
University of Zaragoza, Spain
WG2 leader. Marieke van Erp KNAW
Humanities Cluster, The Netherlands
WG3 leader. Dagmar Gromann
University of Vienna, Austria
WG3 co-leader. Amaryllis Mavragani
University of Stirling, UK
WG4 leader. Sara Carvalho
University of Aveiro, Portugal
WG4 co-leader. Ilan Kernerman
K Dictionaries, Israel

The Action is composed of five working groups (WGs) interoperating and providing mutual feedback. They cover, in a bottom-up approach, the technical and infrastructural groundings needed to attain the objectives of the Action along with a range of use cases and applications. In addition to their own tasks, all WGs participate in preparing cross-group dissemination activities. The scientific work is carried out over four years through workshops and other meetings as well as remote cooperation through electronic communication means (email, teleconference, etc). * Short-Term Scientific Missions (STSMs) organized within each WG, to promote synergies and maximize cooperation, and International Training Schools (ITCs), are not included in this overview.




Click here for the PDF version of this article.

Jorge Gracia
Website
Jorge Gracia is the Chair of the NexusLinguarum ‘European network for Web-centred linguistic data science’ COST Action. He works as assistant professor at the Department of Computer Science and Systems Engineering (University of Zaragoza, Spain) as a member of the Aragon Institute of Engineering Research (I3A) and of the Distributed Information Systems research group. His main research interests are Semantic Web, Ontology Matching, Multilingual Web of Data, Query Interpretation, and Web Intelligence, and his recent work focuses on linked data-based lexicography as well as on methods and techniques for cross-lingual linking and cross-lingual information access.