
News
Home » News
Apr 24
2024

New LLM family from NAVER Cloud HyperCLOVA X
Fascinating report from the NAVER Cloud HyperCLOVA X team on their new LLM family, primarily tailored for Korean language and culture, but (also concerning English and coding, and) potentially useful for sovereign LLMs worldwide, see HyperCLOVA X Technical Report.
Naver is a web giant, often called the “Korean Google”, with substantial international presence mainly in Japan, China, Europe, and USA. It probably owns the most immensely comprehensive Korean language corpora today, which along with its advanced Internet, AI, technological and other expertise, and backed by powerful financial standing, enable it to compete with the top global LLM leaders.
According to the report, the training used “a balanced mix of Korean, English, and code data, followed by instruction-tuning with high-quality human-annotated datasets while abiding by strict safety guidelines.” The model was “evaluated across various benchmarks, including comprehensive reasoning, knowledge, commonsense, factuality, coding, math, chatting, instruction-following, and harmlessness, in both Korean and English. [It] has been developed using systematic red teaming and safety data collection processes [and it] is complemented by extensive safety evaluations, both automatic and human-annotated, to monitor and mitigate the risks of generating harmful, toxic, or otherwise sensitive content.” Besides strong Korean reasoning capabilities, the results exhibit “cross-lingual proficiency and strong generalization ability to untargeted languages, including machine translation between several language pairs and cross-lingual inference tasks [that] can provide helpful guidance for regions or countries in developing their sovereign LLMs.”
Alongside challenging the over-dominance of the English language and English-speaking societies in the LLM advent, what stands out in HyperCLOVA X is its minute attention to numerous details, which foster content reliability and the human-in-the-loop factor, and may signal the approach of more trustful LLMs for professional, business, and public sector services.
In due diligence, Lexicala has cooperated with Naver in several projects, including the provision of high-quality Korean bilingual and multilingual segments for machine learning model making.
Apr 17
2024

SuperMemo completes the release of PowerWords!
Congratulations to SuperMemo for concluding the release of the full set of PowerWords! language learning courses! The set spans 18 languages, each addressing speakers of 15 languages, i.e., including 270 courses in total. The entire process of development has lasted four years.
PowerWords! combine advanced technology with comprehensive language learning data, featuring a unique blend of SuperMemo’s spaced repetition system combined with quality learner’s dictionary data from Lexicala by K Dictionaries. The courses leverage AI and provide definitions, examples of usage, translations, grammatical insights, and recordings of first speakers’ pronunciation. Altogether, PowerWords! forms an immense source of lexical knowledge for many months of intensive learning.
The AI Assistant of PowerWords! accompanies the learners throughout the course, such as to provide more usage examples or explain grammatical details, enhancing self-learning and boosting the user’s confidence and motivation to keep acquiring new vocabulary. Over the last year, SuperMemo has released additional AI-based learning aids, including MemoChat, which enables learners to converse freely in different languages, and MemoTranslator, which incorporates easy translation as well as new phrases into their learning process.
SuperMemo and Lexicala by K Dictionaries launched their collaboration on PowerWords! in 2020, and the courses are continuously refined through user feedback and proofread translations. To celebrate the current milestone, SuperMemo is offering free access to PowerWords! for one month to the first ten applicants. Hurry to unlock your free access with the code ‘LEXICALA’. The code is valid until December 31, 2024.
Apr 9
2024

Lexicala sponsors LREC-COLING 2024
Lexicala by K Dictionaries is proud to announce our sponsorship for the upcoming LREC-COLING 2024 event taking place in Turin, Italy, on May 20-25.
Lexicala has already sponsored separate LREC and COLING conferences before and we are excited to see their two organizers – the ELRA Language Resource Association and the International Committee on Computational Linguistics (ICCL) join forces to organize this unique major event for 2024, which has drawn a record number of 3,302 submissions!
We look forward to seeing you there!
Feb 19
2024

Call for applications for the Adam Kilgarriff Prize, 2024
Applications are now invited for the Adam Kilgarriff Prize. Full information for potential applicants can be found on the AKP website.
The deadline for applications is 30th September 2024. A winner will be announced on or before 31st December 2024, and the Prize will be awarded at the eLex Conference of 2025.
This is the fifth iteration of the Adam Kilgarriff Prize, which has so far had four excellent winners.
Lexicala is a sponsor of the Adam Kilgarriff Prize and Lexicala’s CEO, Ilan Kernerman, is on the Board of Trustees.
Feb 7
2024

Multilingual semi-automated identification and annotation of multiword expressions
This paper presents a new project aiming to develop tools and datasets for the automatic identification of multiword expressions (MWEs) and their annotation and integration in multilingual language settings. We will combine information from quality lexicographic resources and large language model (LLM) outputs along with human curation, to create annotated multilingual lexicons for machine learning-based identification of MWEs. The new resources will serve to identify MWEs and include them in corpus-driven frequency lists for lexicons and lexicographic content that enhance the performance of multiple NLP applications (e.g. (neural) machine translation, word sense disambiguation, parsing, etc), to build a framework that will serve to identify and process MWEs in numerous languages. The project is planned primarily in the context of UniDive WG2 and concerns aspects of multilinguality in WG3 as well.
The main outcomes include:
(1) A framework for MWE discovery and detection (of word form variants), with easy-to-use command line interface (CLI) and a software library offering the key features of model training (based on annotated datasets) and MWE identification (based on the trained models).
(2) Trained models for MWE identification, available for download or via web service, for diverse (types of) languages, such as Dutch, English, Estonian, French, Hebrew, Italian, Polish, Portuguese, Russian, Slovenian, Turkish, and possibly others (related to the language expertise of the project members and to the annotated multilingual lexicon developed as part of the H2020 ELEXIS project.
(3) UD-based annotated datasets for MWE identification for the languages above.
The prediction models that are developed will be exported to other languages and will benefit them too.
NEEDS. While the automatic retrieval of single-word lexicons from corpora is relatively straightforward, extracting MWEs is non-trivial and far more complex, due to the (i) lack of agreement on terminology, (ii) large variety of syntactic structures and semantic ambiguity (e.g. break the ice can be idiomatic but also compositional), (iii) lack of relevant (annotated) data and annotation standards (cf. Rosén et al. 2015), and (iv) lack of effective evaluation methods (mostly for MWE identification). Therefore, MWE lexicons are usually created fully manually, or by using tools that consider only co-occurrence features.
According to Jackendoff (1997), the number of MWEs in a speaker’s lexicon is possibly “of the same order of magnitude as the number of single words of the vocabulary”, and according to Sag et al. (2002) “it seems likely that this is an underestimate.” This emphasizes the importance of substantial coverage and precision of MWE frequency lists and lexicons, for both lexical resources and NLP applications.
WORK. We will first extract MWEs (including examples of usage) from (i) the Global series of K Dictionaries and (ii) LLMs (e.g. ChatGPT, LLaMa, Falcon, mT5-XL), then apply cross-lingual embeddings to match them against corpora (e.g. from Sketch Engine), to list the top 80 most frequent ones per language. Sentences containing candidates for these top 80 MWEs will be automatically extracted from corpora and manually annotated by experts to obtain 25 representative sentences per MWE; more MWEs will be annotated if present in example sentences, so the total number of MWE samples per language will reach at least 2,000.
Alternatively, we might initially pilot fewer languages, depending on those spoken by the participants. The Estonian data could stem from resources of the Estonian Language Institute and the Slovenian from those of Jožef Stefan Institute.
We will then apply deep learning techniques, particularly LLMs, fine-tuned on the training data to discover/detect and tag unseen MWEs. The variation and quality of MWEs that appear in dictionaries, transformed with cross-lingual embeddings and suggestions from massively multilingual language models, will help machine learning models to learn complex MWE patterns (semantic and syntactic) and achieve good generalization for new data.
Recent massively multilingual language models implicitly encode text representations in a latent joint space of many languages. Cross-lingual transfer between different languages is possible by training the models in resource-rich languages, and then the acquired knowledge is transferred to target languages via zero-shot or few-shot transfer. This approach supersedes previous techniques based on explicit static and contextual embeddings that generate explicit numeric vectors for words. We will fine-tune different LLMs on our training set and use them in few-shot transfer for the covered languages as well as in zero-shot transfer mode for uncovered languages. This will reduce the need for large-scale annotation and produce generally useful MWE detectors for many languages.
INTEGRATION. The new tools, datasets, and trained models will become available on the ELG platform.
Acknowledgement
Many thanks to Prof. Marko Robnik Šikonja, Head of the Cognitive Modeling Lab at the Faculty of Computer and Information Science, University of Ljubljana, for his valuable comments and support.
Keywords
MWE identification, MWE annotation, machine learning, models, lexicography, multilingual large language models, zero-shot transfer, few-shot transfer
References
Rosén, V., De Smedt, K., Losnegaard, G. S., Bejček, E., Savary, A., and Osenova, S. 2016.. MWEs in treebanks: From survey to guidelines. Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16).
Jackendoff, R. 1997. The architecture of the language faculty (No. 28). Boston, MA: MIT Press.
Sag, I. A., Baldwin, T., Bond, F., Copestake, A., and Flickinger, D. 2002. Multiword expressions: A pain in the neck for NLP. In International conference on intelligent text processing and computational linguistics. Berlin, Heidelberg: Springer, 1-15.
Dec 20
2023

Visit to the Center for Digital Lexicography of the German Language in Berlin
Lexicala CEO, Ilan Kernerman, visited the Center for Digital Lexicography of the German Language (Zentrum für digitale Lexikographie der deutschen Sprache, ZDL), based at the Berlin-Brandenburg Academy of Sciences and Humanities (BBAW) for meetings with the local team, headed by Dr. Alexander Geyken, and discussions on possible collaboration.
Funded by the German Ministry of Education, the mission of ZDL is to develop and operate a lexical information system presenting contemporary German vocabulary in an up-to-date, comprehensive and reliable manner, based on massive linguistic data accumulated since the early 17th century to modern times. BAWW coordinates the scientific cooperation of ZDL with the Lower Saxony Academy of Sciences and Humanities in Göttingen (NAdWG) and the Leibniz Institute for the German Language in Mannheim (IDS). In the long term, the project will continue with the support of the four academies in Berlin, Göttingen, Leipzig and Mainz, as well as IDS. Other partners include the Austrian Academy of Sciences (ÖAW), the Swiss Academy of Humanities and Social Sciences (SAGW) and the Trier Center for Digital Humanities (TCDH).
The Berlin section of ZDL operates the entire technical infrastructure, prepares the language data required for scientific lexicography, compiles the contemporary dictionary articles, and develops computational linguistic tools for the automation of lexicographic work. These tasks are currently being carried out in conjunction with the academic project Digitales Wör-terbuch der deutschen Sprache (DWDS), which will expire in 2025 and be continued as part of ZDL.
The project results are open to the general public via the websites of ZDL and DWDS. They contain 600,000 entries derived from contemporary and historical dictionaries, diverse reference sources, general media, and web corpora including 60 billion tokens, and also feature statistics on word combinations, regional distributions of words, and time lines. With around 10 million page views per month, DWDS is one of the most-visited reference sites on German language in German-speaking countries, and it’s regularly used in university research and teaching and as a professional reference tool in numerous domains, particularly those of education, the media and literary translation.
Dec 7
2023
University of Vienna students’ internship at Lexicala
We are excited to share the news of our collaboration with the University of Vienna.
It’s a pleasure to welcome to our internship program three MA students of Multilingual Technology, with the help of Prof. Dagmar Gromann.
The interns – Karin Niederreiter, Bettina Pátzay, and Nadezda Sazanova – have started to explore three challenging projects on hate speech and offensive language. Their work involves experimental computational linguistics tasks on English, German, Hungarian and Russian vocabularies.
The results of these research projects are expected to be made available toward the end of Q1, 2024.
Nov 24
2023

WordPlay Games, word puzzle video games with Lexicala resources
WordPlay Games have released a new line of SpellStruck word puzzle video games for five languages, including definitions from Lexicala monolingual resources.
The games display word definitions from Lexicala in Spanish, German, French, Italian, and Brazilian Portuguese, adding to the popular English-language application that was released earlier this year and features definitions from Wordnik.
Spellstruck, featuring Disney characters, is available on the Apple Arcade subscription service.
Nov 21
2023
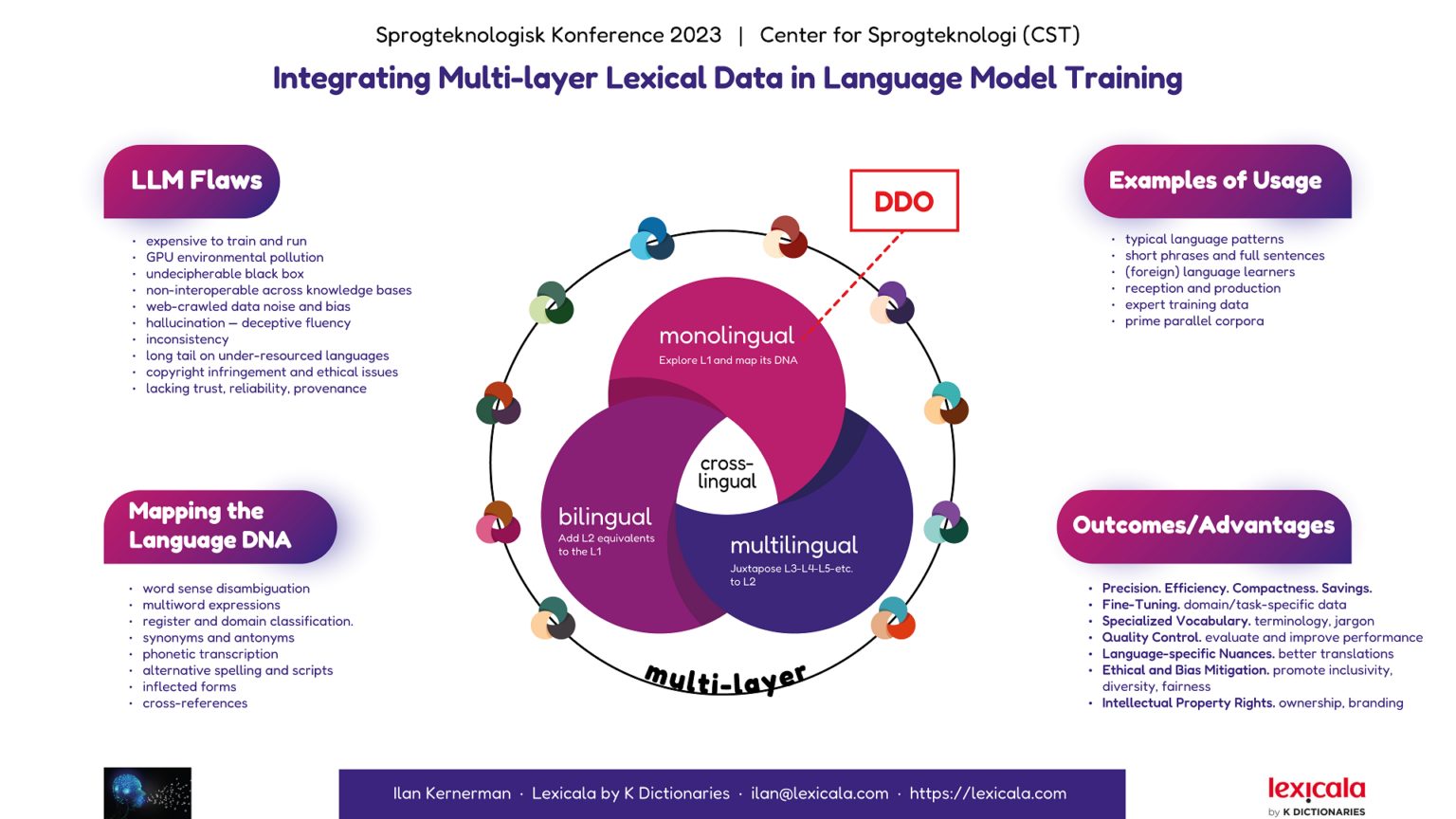
Presenting a poster on LLM training data at Copenhagen University Language Technology Conference
Winter is coming, and Lexicala CEO, Ilan Kernerman, is heading to the cold north but heartwarming annual conference of the Language Technology Center at Copenhagen University (CST). Sprogteknologisk Konference 2023 will be held on Thursday, November 23, bringing together local and foreign developers, researchers, users and students, and featuring diverse talks on language-centered AI.
Ilan will present a poster entitled ‘Integrating Multi-layer Lexical Data in Language Model Training,’ which describes the unique characteristics of Lexicala’s multi-layer language data and how they can enhance the training and performance of LLMs and MT systems, as well as other NLP applications.
Our innovative multi-layer method converges human creation and curation with automated data processing. It starts with the meticulous exploration of the foundations of each language, and the evidence that is gathered and diagnosed enables “mapping its DNA” minutely to create a monolingual core. Then we proceed to add L2 equivalents, to produce a bilingual pair, and juxtapose more language translations forming a multilingual layer around the initial L1 core. This core and its multilingual satellites can be further cross-lingualized and extrapolated across other language networks, all relying on a comprehensive technical infrastructure and overall framework.
Besides the usual sense disambiguation, definitions, examples, and multiword expressions, the data features rich semantic and syntactic information including morphology lists linking inflected forms to main lemmas, offensive language taxonomies, domain and register classification, synonyms and antonyms, grammatical details, phonetic transcription, spelling variations, alternative scripts, cross-references, etc.
The most relevant for LLMs and MT are the usage examples that stem from traditional learner’s dictionaries. They are conceived by experts who identify typical language patterns and design short phrases and full sentences that illustrate their use for (foreign) language learners.
Incorporating such quality lexical resources in the initial stages of language model training exceeds feeding masses of data for LLM training, offering the advantages of efficiency, precision, compactness, savings (work, time, costs), and copyright issues.
Moreover, shifting the emphasis to the preliminary model training phases also moderates the needs for excessive (Automated) Post Editing and Quality Estimation and the challenges originating from LLM hallucination, bias, and inconsistency.
The poster will highlight the prime Danish language resource of Lexicala, which is based on data from the legacy Den Danske Ordbog (DDO, The Danish Dictionary), of the Society of Danish Language and Literature (DSL).
Over the years we have substantially revised and adapted the DDO entries to create the Danish monolingual layer in our Global series, and it has since served as a base for developing bilingual and multilingual layers, including a trilingual Danish-English-Korean dataset that we tailor-made in 2018-2020 for Naver corporation in Korea, with the help of Lexical Computing.
It’s been a while since my last visit to Copenhagen, well before the Covid-19 outbreak. I look forward to meeting our colleagues at CST and making new acquaintances!
Oct 12
2023

Distribution agreement between ELDA and Lexicala for the dissemination of multilingual lexical data.
We are happy to announce that ELDA, the European Language resources Distribution Agency, is starting to disseminate the language resources of Lexicala to its clients.
To read more, please go to: ELDA PR
Oct 4
2023

Taus conference 2023, Salt Lake City
Lexicala CEO, Ilan Kernerman, is attending the TAUS annual conference in Salt Lake City, meeting with industry experts, learning about the implications of Large Language Models for Machine Translation, and presenting our relevant work at Lexicala.
Ilan is honored to take part in a panel discussion on the Localization Business – The Provider Perspective, along with Mathijs Sonnemans (Blackbird.io), Spence Green (Lilt), Jeffrey Jean-Paul Kiser (Acolad) and Jan Gordecki (WeLocalize), moderated by Renato Beninatto (Nimdzi).
Ilan will also attend a pre-conference workshop on GenAI in Localization, to gain insights on the emerging landscape of LLMs, including governance and risk management, and explore use cases and applications.
Last but not least, Ilan will showcase the innovative methods and added value of Lexicala in the AI Revolution Readiness Contest, alongside leading MT professionals, focusing on the vital role of quality lexical data for fostering LLM training and performance.
Sep 7
2023

The fifth plenary meeting of NexusLinguarum
Milan, Italy
Lexicala CEO, Ilan Kernerman participated in the fifth plenary meeting of NexusLinguarum that was held at Università Cattolica del Sacro Cuore in Milan, Italy on September 7-8th 2023.
This COST Association – European Cooperation in Science and Technology Action, on building a European network for Web-centred linguistic data science, will end next April, and there is a lot of work on planning the final stages. A big part of the meeting was thus devoted to the Roadmap track and Lexicala CEO chaired a session on industry adoption of LLD (Linguistic Linked Data), with good help from Dimitar Trajanov.
While distinguishing it from LLOD (Linguistic Linked Open Data), the participants explained how LLD is adopted in the industry and its benefits, as well as the mutual contribution to and from LLMs that open new ground and exciting possibilities.
Aug 28
2023

LITHME WG1-WG7 Joint Workshop in beautiful Budapest on:
‘Bridging the gap between technology and professionals’
Lexicala CEO, Ilan Kernerman present in the LITHME WG1-WG7 Joint Workshop at ELTE University Budapest, on August 28.
Ilan talks about ‘Human-in-the-loop in Language Technology’.
Ilan is happy that his kick-off talk, Human-in the-loop in Language Technology, had such good reviews.
Ilan enjoyed in particular the excellent keynotes by Cristina España i Bonet España-Bonet, from the Deutsches Forschungszentrum für Künstliche Intelligenz (DFKI), on Human Biases in Multilingual Systems, and by Győző Yang, from the Hungarian Research Institute for Linguistics, on “Large Language Models in Modern Machine Translation: How Are They Reshaping the World of Machine Translation?”.
Aug 9
2023

Bad words?
A few years ago, together with our partners at Cambridge University Press, we updated the editorial policy and methodology for detecting and labeling informal, colloquial and slang language, putting an emphasis on vulgar and offensive terms and expressions, which we nicknamed bad words.
The project consisted of editing our entire lexical resources for all languages. Rather than remove and avoid such items altogether, our aim remained to record these items in the data as part of a descriptive approach that helps to provide richer and deeper understanding of the language, of the way it functions, and of how speakers and writers communicate in “real life”.
The rationale is that, although such terms are generally considered to be problematic, we cannot ignore their existence, but must learn how to present and illustrate them respectfully, faithfully, and consistently. Moreover, we believe that this attitude can be useful and effective in many ways.
Recently, Lexicala’s team members participated in the eLex conference at Brno (Electronic Lexicography in the 21st Century). One of the interesting presentations there was by Carole Tiberius from the Dutch Language Institute on the topic of taboo language.
Carole and her colleague, Gerhard Van Huyssteen, are compiling a comprehensive lexical database of over 5,000 lemmas of Dutch ‘taboo’ terms, and she described the resources, concept, and potential usage of their project.
We view this talk as strongly supporting the merits of taking our own smaller and denser pool of ‘bad words’ and expanding and broadening it.
Our existing database can evidently contribute far more than just to illustrating terms that are socially problematic and – by mapping, labeling, and presenting them adequately – we can apply it to assist more fields of NLP and machine learning, for example to help to recognize hate language or abusive web content.
There is also great added value in enhancing our pragmatic-related fields of knowledge relating to informal and taboo language, such as for identifying intention (of speaker) and perception or influence (on recipient).
Jul 24
2023
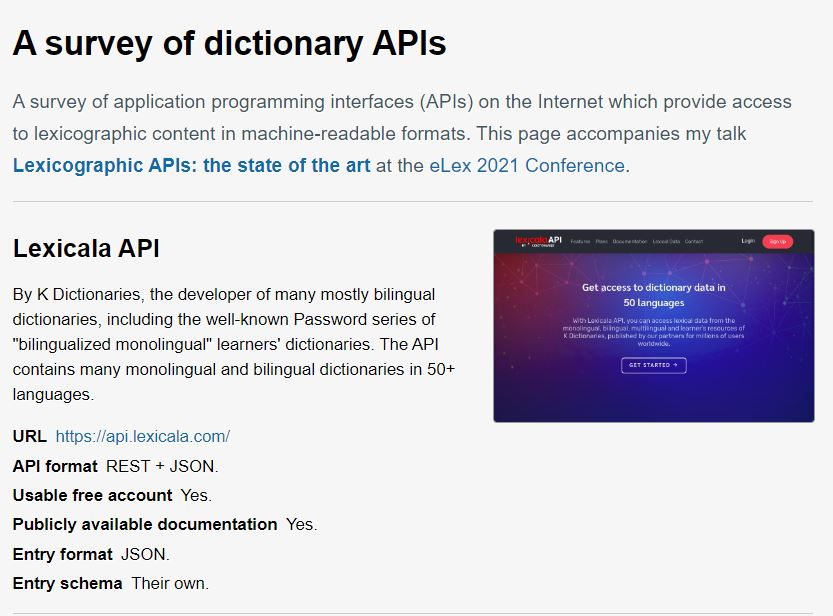
Why Lexicala API?
Two years ago, in July 2021, Michal Měchura published a survey of dictionary APIs:
In this survey, Lexicala API stood out as the best and preferred leading option in the market.
Since then, we have continued working closely with our clients to improve and add new features like:
- Synonym parameters
- access frequency data
- Response time
- Scaled calls for our premium users
Jul 19
2023

Update in Lexicala API:
New frequency feature through the search and entries endpoints
We are excited to announce an update in Lexicala API, with a feature that allows you to access frequency.
We have added the new feature to allow you to access frequency data for words when using the /search and /entries endpoints.
Frequency information provides valuable insight into the usage and prevalence of words in various contexts. With this update, you can now retrieve frequency information with the dictionary entries, enhancing your language analysis and research capabilities.
Jun 27
2023

Lexicala at eLex 2023
eLex 2023 was held in Brno on June 27-29 and attended by Lexicala’s Vova Dzhuranyuk, Anna Kernerman, and Ilan Kernerman.
The main theme in this ‘electronic lexicography in the 21st century’ conference was Invisible Lexicography, and many sessions discussed the effects of ChatGPT on lexicography.
In his talk, Ilan highlighted the potential of lexicography for LLMs, focusing on translation.
Jun 24
2023

Lexicala CEO, Ilan Kernerman, spoke at the Asialex 2023 conference in Seoul on June 24 on the evolution of contemporary lexicography and its interaction with AI.
First, Ilan presented the innovative milestones of pedagogical lexicography in the 20th century, highlighting the pioneering research into phraseology and the design of examples of usage that portray typical language patterns;
the rise of corpora, followed by smart corpus query systems and applications, and their implications on deep language analysis and unbiased replication and reproduction; and the introduction of translation equivalents in the advent of bilingual learner’s dictionaries for both reception as well as production purposes.
He explained that these milestones converge with the traditional assets of legacy dictionaries, which have earned them the trust of the public as authoritative and reliable language instruments, and how they opened new horizons in the turn of the millennium to multilingual lexicography and interoperability with modern language technology, data science, and knowledge management.
In consequence, today, quality lexicographic sets can offer unique added value to enhance the training of large (and other) language models, and refine and reinforce LLM performance.
Ilan described how the multi-layer approach of Lexicala by K Dictionaries, building bottom-up and cross-lingually from any language to any other, is combined with human created and curated content and automated data generation and processing, and how such methods and resources can benefit AI.
Jun 7
2023
Lexicala intern interview
Lexicala’s Content Manager Anna Kernerman (AK) spoke with Zuzanna Klyszcz (ZK), a BA student at the Institute of Modern Language Studies, State University of Applied Sciences in Racibórz (PWSZ), Poland, who has completed a six-month internship at Lexicala, during which she handled a project of translating German dictionary entries into Polish.
AK: Tell me a bit about yourself – in general, your academic background, or anything you’d like to share.
ZK: My name is Zuzanna and I am 22 years old. I am completing a bachelor’s degree in German studies and working on my thesis, which is almost done. I also work in an international company as a customer service provider in German. Besides, I’m interested in sports, working out, and traveling, and I speak four languages.
AK: What languages do you speak?
ZK: My mother tongue is Polish, and my second language is German, in which I’m almost fluent. I’m also nearly fluent in English and I speak Italian at an intermediate level.
AK: Do you have other interests in the field of German studies besides the language itself?
ZK: In my university, there isn’t much focus on German literature, only in the first year. The program is mostly on translating, or on German for business. The studies of German philology aren’t focused on literature or history, but rather on German in “real life”. We learn things that can be useful when we graduate. I feel very fortunate since I have friends who study philology at other universities, but their studies for the entire bachelor’s three-year period have no classes on translation. To become a translator, you should either choose a great university or start working in a translation office, for which you need some experience. Therefore, it’s good to have an internship, like what I did here [in Lexicala].
AK: So, your aim or main interest when you started studying, was translation.
ZK: Yes, as well as the German language in general. I’m also interested in the business side, for practical purposes, not just theoretical ones.
AK: What got you interested in languages – or more specifically, in German – in the first place?
ZK: German is my first foreign language. I absorbed it by watching German TV and learned to speak it fluently. When I started studying at university, I was surprised that all the other students learned German in the same way. If I would have not started learning German at such a young age, I wouldn’t be able to speak German as fluently since it’s such a difficult language; at school, you can learn the basics, but you should work on it also at home by yourself.
AK: Let’s talk about your internship. How did you come across the internship program at Lexicala?
ZK: I heard about this two years ago, in 2021, when we had to do an internship to pass our university class. By that time, I did remote work in customer service, at a company in Warsaw, 400 kilometers away from where I live. Now, I thought about having my internship with them too, but finally decided on Lexicala. Happily, there was a place for me, so I was glad to have this internship. This is also remote, as it could have been difficult working between Israel and Poland [laughs]. I’m glad we finally met; I really liked this internship.
AK: I’m happy to hear this. How was the process of applying for the internship, in regard to Lexicala or your institute?
ZK: When it comes to the application, the only thing my professor wanted to know was what languages I speak, and at what level. I told her my German is C1, and English is B2 or C1. So she said, alright, let’s see what we can do for you. Then I received the [contract] to sign, saying the internship starts in October and finishes in April. That was it.
AK: Tell me about the project you were handling.
ZK: I translated words, expressions, short phrases, and full sentences, working on Word files, each about forty pages long. The headwords were in German, and I post-edited the Polish translation equivalents. In addition, I had to choose their grammatical gender. The internship was not based only on what I already knew, but I also had to use other sources to translate correctly, for example, phrasal verbs that I was not familiar with.
AK: How do you think you have benefited from this translation project professionally?
ZK: I knew there were things I know, which I could translate without any [external] sources. But I also realized that even if I am fluent in a language, I still need to ask for help. For example, in the beginning, I was not sure how to start, so I contacted you; you said I should do this and that and I was like, “Okay, that sounds easy”. I realized that I don’t have to be the smartest person in the world, and it’s okay to consult with others and ask for advice – not to worry about asking for help.
AK: How did this work contribute to you academically or personally? For example, you mentioned the value of having broader knowledge about the language itself, not only translation skills.
ZK: In view of the format of the dictionary, I haven’t had a specific text to translate, such as a paragraph composed of several sentences. There were individual entries, and I had to translate each headword, sometimes having different meanings [i.e., senses], and to get its full context. That helped to improve my creativity.
AK: Would you recommend this internship to fellow students?
ZK: Yes, certainly. In the beginning, everyone has difficulties. But once you complete the first file, and your supervisor says it’s done well and you can proceed with the next one, you have the motivation to complete your project. If I study for another degree in the future, or have an opportunity to do something similar, I will surely agree to it.
AK: I remember our long correspondence over the first two or three files you sent me, for which I had many comments. But once you “absorbed” them, there was no problem, like you did it effortlessly.
ZK: Yes, the last files had no comments of yours at all, so I thought, “Good, I must’ve learned something”. You just have to learn from your mistakes.
AK: As you know, not many professional translators have experience with translating dictionaries or other lexicographic content. That’s some important knowledge you have acquired. Do you think you’d be interested in having other, similar translation projects?
ZK: Yes, indeed. I’m not sure what I want to do later in life, but I know I want my language skills to be part of my professional future. I am currently working in customer service, but this is not for the rest of my life. I would like to combine several things together, but they should be related to language. For example, working in a company as well as having translation projects, like documents or dictionaries. That would be perfect for me.
AK: Would you change anything in the way the internship was handled?
ZK: I would have liked the files to be smaller, to finish each document as soon as possible. I wanted to correspond with you every few days, because if I didn’t write you in, say, two weeks, you wouldn’t know what was up with me. So, I’d rather have documents with fewer pages, and keeping more regular contact with you.
AK: The batch of files you translated was only one part of our German-Polish dataset. Translating a dictionary is a long process, which can take months, even years, to complete. So, your work might not be published any time soon as we would need to complete the full dataset first.
ZK: Some internships are stationary, where you hear stuff like “Make us some coffee”, or “Organize these papers”. But when I started this internship, I saw there was real work to do. Maybe in the future someone will revise my work, but I also get the feeling that it is meaningful, and it makes sense.
AK: Is there anything you’d like to add or ask?
ZK: If you were a student, would you like to take part in this type of project, or would you reject it?
AK: I think I would find it interesting. I’m a student of linguistics, so I think it’s a bit different. In linguistics, we are interested in fields that aren’t necessarily related to translation or lexicography. Still, if I were offered an internship of this kind, I think I’d accept it. Again, this work can be very difficult and Sisyphean, but it’s very valuable and you can gain a lot from it.
ZK: Yes, not only in your resume, but you can get something out of it personally.
Jun 6
2023

Asialex 2023
Lexicala CEO, Ilan Kernerman, will speak at Asian Association for Lexicography, (ASIALEX 2023), in Yonsei University, Seoul.
On June 23 about Lexicography lost and found: From dictionaries to AI.
May 17
2023


University of Zurich’s Department of Computational Linguistics meet with Lexicala
The Lexicala team met online yesterday with an international group of MA students from the University of Zurich’s Department of Computational Linguistics, led by Professor Martin Volk and his colleagues.
First we were introduced to the diverse NLP studies and research going on at the Institute, such as their impressive avatar demonstrating Swiss German Sign Language.
Then we presented a broad overview of Lexicala resources, tools and applications, as well as our related development methods and concepts, which are aimed to enhance language technology solutions, including language models and machine learning.
May 15
2023

SALLD-3 @ LDK 2023 – Third workshop on Sentiment Analysis and Linguistic Linked Data
The program of SALLD-3, the third workshop on sentiment analysis and linguistic linked data, is ready.
This half-day workshop will provide a forum for discussion about the integration of Linguistic Linked Data principles in the Sentiment Analysis field, with the aim of exploring related methods, resources, tools and applications, and case studies.
SALLD-3 will be held in conjunction with the fourth conference on Language, Data and Knowledge – LDK 2023 – at the University of Vienna on September 12, 2023. It’s supported by NexusLinguarum COST Action (CA 18209 European network for Web-centered linguistic data science), and it will feature two invited talks from academia and two from industry, as well as three submissions that were peer-reviewed and accepted.
The academia invited talks were generated from ongoing work in NexusLinguarum, including:
- Offensive language simplified taxonomy as a LOD schema in multilingual detection and applications, by Barbara Lewandowska-Tomaszczyk, Anna Bączkowska, Olga Dontcheva-Navrátilová, Chaya Liebeskind, Giedrė Valūnaitė-Oleškevičienė, Slavko Žitnik, Marcin Trojszczak, Renata Povolná, Linas Selmistraitis, Andrius Utka and Dangis Gudelis; and
- Czech offensive language taxonomy, by Olga Dontcheva-Navrátilová, Renata Povolná and Slavko Žitnik.
The industry invited talks are the following:
- Rapid AI-based detection of aggressive or radical content on the web, by Artem Revchenko (Semantic Web Company) and Alexander Schindler (Austrian Institute of Technology); and
- Enterprise multilingual knowledge management: Lessons learned and ways forward, by Felix Sasaki (SAP).
In addition, the three accepted talks are:
- Valence and arousal-based sentiment analysis: A comparative study, by Usama Shahid and Muhammad Zunnurain Hussain;
- Sentiment analysis with emojis: A model for Brazilian Portuguese, by Raquel Freitag, Julian Tejada, Vinícius Moitinho da Silva Santos, Ayla Santana Florêncio, Pedro Paulo Oliveira Barros Souza and Túlio Sousa Gois; and
- SLIWC, NarrOnt and Senpy annotations: Three vocabularies to fight radicalization, by J. Fernando Sánchez-Rada, Guillermo García-Grao, Óscar Araque and Carlos A. Iglesias.
The SALLD series was launched in 2020 by Lexicala CEO, Ilan Kernerman, in the context of NexusLinguarum Working Group 4 (WG4: Use cases and applications, where he is co-leader), and was inspired in particular by the use case on Media and Social Media, coordinated by Professor Lewandowska-Tomaszczyk, of the State University of Applied Sciences in Konin, Poland (UC4.1.1). SALLD-1 was held as part of LDK 2021 in Zaragoza.
Ilan was joined in co-organizing SALLD-2 by Nexus W4 leader, Sara Carvalho (University of Aveiro, Portugal) as well as by Rachele Sprugnoli (University of Parma, Italy), and Carlos A. Iglesias (Madrid Polytechnic University, Spain). It was held in conjunction with LREC 2022 in Marseille.
SALLD-3 is co-organized by Ilan and Sara.
Apr 20
2023
On April 20, Kris Heylen, from the the Dutch Language Institute (INT), presented the paper co-authored with Lexicala’s Ilan Kernerman and INT’s Carole Tiberius – Linking CEFR-based learner profiles to lexicographic data – at the L2P-2023 workshop at the University of Gothenburg (Workshop on Profiling second language vocabulary and grammar – 2023).
The talk was our first public presentation for 2023 of the project for linking lexicographic and language learning resources, which is being developed together by INT, Lexicala by K Dictionaries, and the Institute of Estonian Language (EKI).
This cooperation began with Ilan’s 10-day visit to INT in Leiden in April 2022, hosted by Carole and Kris, as part of an STSM (Short-Time Scientific Mission) in the framework of NexusLinguarum COST Action (CA18209, European network for Web-centered linguistic data science). EKI’s Jelena Kallas joined us a couple of months later, and we presented the initial stage of our research – Linking lexicographic resources to language proficiency-level applications – at the NexusLinguarum-sponsored conference LLODREAM2022 (LLOD approaches for language data research and management) in Vilnius on September 21.
The aim of this project is to foster the research and development of a new generation of multilingual language teaching, learning, and assessment materials, particularly focused on CEFR grading. CEFR stands for Common European Framework of Reference for Languages: Learning, teaching, assessment. We embrace a holistic approach, converging lexicographic and language learning resources with NLP applications, linked data methods, semantic technologies, and generative AI testing and prompting. To achieve this goal, we plan to establish a consortium of partners from the industry and academia with related competences.
Our next presentations will be online on May 13, as part of the Spring Forum of the Japan Association of English Corpus Linguistics, SIG Corpora and the CEFR, organized by Yukio Tono from Tokyo University of Foreign Studies, including the following talks:
- Linking lexicographic and CEFR resources. (Kris, Ilan and Carole)
- Methodological issues regarding a corpus-based analysis for the development of the CEFR Grammar Profiles for Estonian. (Jelena)
- Towards an infrastructure for the semi-automatic development of corpus-based language exercises. (Katrien Depuydt and Jesse de Does, INT)
In addition, we are organizing two workshops, where more experts will present their corresponding work. The first – Lexicography and CEFR – will be held in conjunction with the eLex 2023 conference at Brno, Czech Republic, on June 29. The second – Linking Lexicographic and Language Learning Resources (4LR) – will be held in conjunction with the Language, Data and Knowledge conference (LDK 2023) in Vienna, on September 13.
Mar 29
2023

Lexicala’s CEO, Ilan Kernerman, will attend BETT 2023 in London this week. Bett is the leading global exhibition on educational technology.
Ilan will be meeting with international providers of language learning solutions to discuss cooperation on implementing Lexicala resources in their products and services.
Mar 8
2023

New Synonym Feature in Lexicala API
We are happy to inform that Lexicala API features a new SYNONYM parameter, which enables searching entries by synonyms and makes it easier to find the results you need, even if you’re not sure of the exact words to use. To use the synonyms feature, set it to True.
As always, if you have any questions or specific needs, please reach out to our support team and we’ll be happy to assist you.
Feb 15
2023

Ilan Kernerman completes term on IAHLT board of directors
The Israeli Association of Human Language Technologies (IAHLT) is a non-profit organization established in 2020 with the support of Israel Innovation Authority and National Digital Israel Initiative. Its aims are to build and provide expert open source content, tools and applications for Hebrew and Arabic NLP, and it includes members from the language technology industry and local academia.
Lexicala by K Dictionaries has been closely involved in the establishment of IAHLT and in its work. Now, Lexicala’s CEO, Ilan Kernerman, has completed his term on the Board of Directors, while former employees – Noam Ordan and Yifat Ben Moshe – continue to lead the working teams in developing the Hebrew and Arabic NLP and speech R&D infrastructures.
By the end of 2022, IAHLT has released 100,000 NER and 40,000 UD/morphology tagged sentences for Hebrew and 160,000 NER and 4,000 UD/morphology tagged sentences for Arabic, and the goal for 2023 is to complete tagging 50,000 UD/morphology sentences for each language. In addition, IAHLT offers smart automatic UD/morphology tagging tools for Hebrew and Arabic.
Oct 22
2022

Ilan Kernerman talks about Lexicography lost and found: From dictionaries to NLP and AI at Kyungpook National University, South Korea
Lexicala CEO Ilan presented the evolution of modern lexicography, its status, and prospects.
The talk began with an overview of the major lexicographic breakthroughs in the twentieth century, related to learner’s dictionaries and the rise of English as the lingua franca, and including the advent of corpus and multilingual lexicography.

Entering the new millennium is characterized by massive technological innovations and the process of globalization, marking a passage from print to digital, opening new channels for experts and users, and leading to enhanced multidisciplinary and interoperability.
Today the balance keeps changing between dictionaries and lexicography, and among them and natural language processing, understanding and processing, semantic technologies, data science and knowledge management, machine learning, language models and artificial intelligence.
Oct 12
2022

Lexicala is Sponsor of COLING 2022 in Gyeongju
Levxicala is proud to be a sponsor of the 29th International Conference on Computational Linguistics, COLING 2022, at Gyeongju, South Korea, September 12-17.

Review the summary on COLING 2022 on our Lexicala Review.
Oct 11
2022

Karni Berlad Cohen participates in TAUS Massively Multilingual Conference & Expo at San Jose, CA
Lexicala Marketing Director, Karni Berlad Cohen took part in the conference and exhibition and presented Lexicala’s ‘expert multi-layer, cross-lingual data for massively refined machine translation’ in the World-Readiness Contest.
The presentation was about developing Lexicala’s language data resources by converging manually created content with smart automated processes topped by human curation. The Lexicala model applies one overall framework and its underlying technical infrastructure to generate expert bilingual and multilingual parallel corpora that serve to refine neural machine translation systems for any language – as source, target, or pivot – relying on deep lexical mapping and including sense alignment, domain classification, morphology, and annotation services.
For more information about the conference, visit the TUAS.
Sep 6
2022

30th Anniversary of Lexicala Review
Originally launched in 1994 as Password News, this four-page annual newsletter was renamed Kernerman Dictionary News, grew in size and readership and has become over the years the most widely circulated independent publication on contemporary lexicography worldwide.
Led by Ilan Kernerman and now available online only, the renamed Lexicala Review has expanded its scope to cross-lingual language data and technology and it consolidates the industry trends, challenges and developments.
All the articles and all 30 issues are available on Lexicala Review.
Sep 5
2022
Lexicala Launches New Multilingual Lexical Data Solutions for Natural Language Processing and Machine Learning
Published in multiple places.

Feb 2
2022
Lynx knowledge-based AI service platform featured in Information Systems journal
The article presenting the partners from the Lynx consortium. It describes the creation of a knowledge graph for the legal domain and its use for the semantic processing, analysis, and enrichment of documents, as well as the use cases covered in Lynx, the entire developed platform and the semantic analysis services that operate on the documents.
Lynx – Legal Knowledge Graph for Multilingual Compliance Services – was a 40-month research and innovation project held in the framework of the EU Horizon 2020 program and completed in March 2021.
Led by the Ontology Engineering Group of Madrid Polytechnic University and including ten more commercial and academic partners, the main objective of Lynx was to create an ecosystem of smart cloud services to better manage compliance, based on a legal knowledge graph that integrates and links heterogeneous compliance data sources including legislation, case law, standards, and other private contracts.
Dec 29
2021

Parallel Corpora for better Korean Translation
Naver Corporation will integrate over a quarter of a million sentence pairs from K Dictionaries to enhance the performance of Papago Translator and Naver Dictionary services.
Papago is the world leader in Neural and Semantic Machine Translation for Korean and 13 languages, and is available on the Web and in mobile apps for professional and personal use.
Naver Dictionary is the common dictionary service in Korea, including 49 bilingual dictionaries, and recently it launched the English Dictionary service that features renowned dictionaries from leading American and British publishers.
The Lexicala Korean parallel corpora stem from quality lexicographic resources of K Dictionaries and are applied to training machine learning models and to Naver dictionaries. It consists of 260,000 bilingual examples of usage from dictionary entries between Korean and four major Western languages: English, French, German, and Spanish. The data is developed by converging human created and curated content with smart automated processing methods, including the review of all the sentence pairs by Korean
language experts to assure perfect matching equivalence to the other languages.
Naver and K Dictionaries began to cooperate in 2017 on the development of Korean trilingual dictionaries and plan to expand their collaboration on Naver’s new Open Dictionary Platform.
Nov 2
2021

SuperMemo publish Czech and Greek PowerWords!
SuperMemo World launched new language courses in the PowerWords! vocabulary learning series for Czech and Greek. PowerWords Čeština and PowerWords! Ελληνικά include versions for speakers of Chinese, English, French, German, Italian, Japanese, Korean, Polish, Portuguese, Russian, and Spanish.
The PowerWords! series integrates lexicographic content from Lexicala and the languages covered so far include Arabic, Chinese, Czech, Danish, Dutch, English, Finnish, French, German, Greek Hungarian, Italian, Japanese, Norwegian, Polish, Portuguese (Brazilian and European), Russian, Spanish, and Swedish. More language courses are in preparation.
Oct 27
2021

Sales of parallel corpora for machine translation
We are delighted to announce the first sale of Lexicala parallel corpora on TAUS Data Marketplace. The bilingual datasets, for English-Korean and English-Turkish, will serve to train machine learning models for neural machine translation (NMT) systems.
Unlike most big data that is harvested on the Web for this purpose, but often contains various types of noise and shortcomings, the Lexicala resources converge human curated and automatically generated sentences, stemming from examples of usage that are translated by our editors, which can serve to enhance the quality of NMT processes and their results.
The TAUS Data Marketplace is a pioneering platform for exchange between data sellers and buyers, used by major Language Service Providers worldwide. Currently it features 357 language pairs by Lexicala, which make us its biggest provider of parallel corpora for NMT.